Hoje a Internet Parou por Culpa da Cloudflare: Entenda o Que Aconteceu e Como Isso Afetou Sites Famosos
A internet enfrentou instabilidade global após uma falha na Cloudflare. Veja o que causou o problema e como vários sites famosos foram afetados hoje.

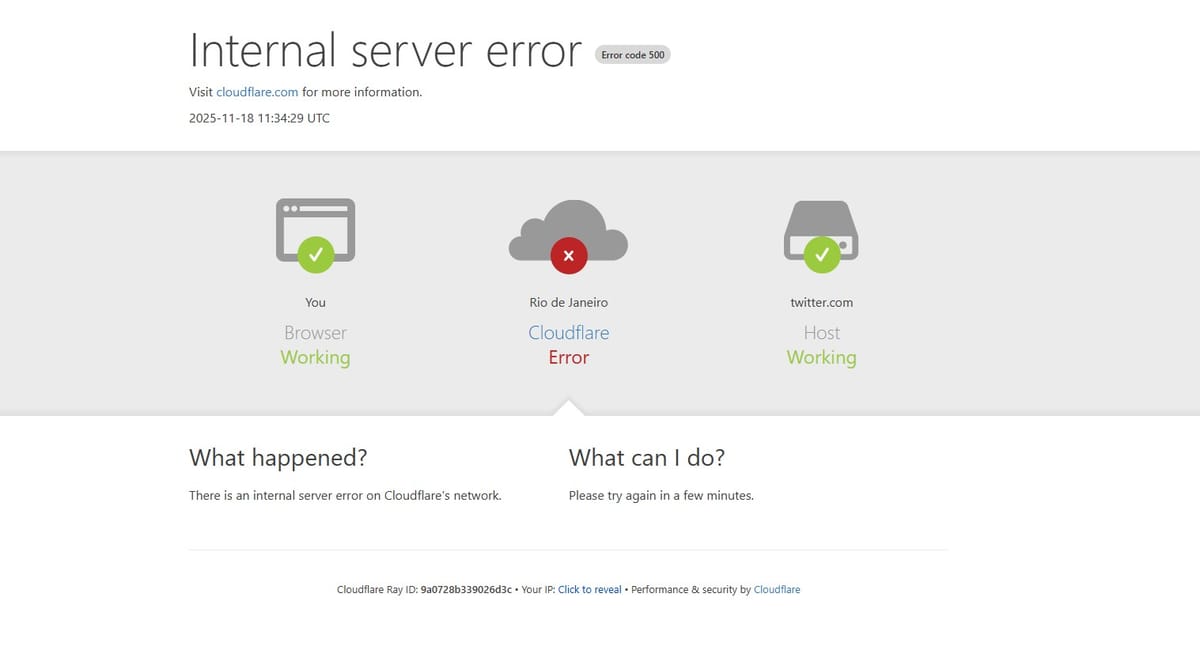
Na manhã desta terça-feira, 18 de novembro de 2025, a internet passou por uma das maiores instabilidades recentes. Milhares de sites e aplicativos começaram a apresentar erros, lentidão ou simplesmente ficaram fora do ar. A causa? Um problema em um nome que muita gente nunca ouviu falar: Cloudflare.
Mesmo pouco conhecida pelo público geral, a Cloudflare é um dos pilares mais importantes da infraestrutura da internet moderna. Quando algo dá errado nela, o efeito chega a praticamente todos os cantos da web.
O que é a Cloudflare (explicado de forma simples)
Para quem nunca ouviu falar, a Cloudflare funciona como um “intermediário inteligente” entre você e o site que está acessando. Ela acelera, protege e organiza o tráfego de acessos, garantindo que os sites carreguem mais rápido e fiquem seguros contra ataques.
Em termos simples, ela atua como:
- um filtro contra hackers e tráfego suspeito;
- um acelerador que encurta caminhos entre você e o site;
- um escudo que impede que ataques derrubem páginas;
- um organizador de tráfego, distribuindo acessos para evitar lentidão.
Hoje, cerca de 20% dos sites do mundo dependem dela de alguma forma.
Quando ela falha, uma parte significativa da internet falha junto.
Explicação técnica para leitores avançados
A Cloudflare opera como uma extensa camada de reverse proxy, CDN global, firewall de aplicação, mitigação de ataques DDoS, gerenciamento de bots e DNS Anycast.
Ela está presente em centenas de cidades, atuando como a “borda” da internet para milhões de domínios.
Hoje, o componente afetado foi justamente um dos mais sensíveis: o módulo de filtragem automática de ameaças (bot management / regras dinâmicas).
O que aconteceu hoje
Segundo fontes internacionais (Reuters, Financial Times e Washington Post), o incidente começou por volta das 09h40 UTC. A Cloudflare confirmou que não foi um ataque cibernético.
A causa foi uma falha interna bem específica:
Um arquivo de configuração gerado automaticamente, responsável por gerenciar tráfego suspeito, cresceu mais do que o esperado e travou parte do sistema que processa requisições.
Isso provocou erros em cascata ao redor do mundo.
A Cloudflare informou que a situação foi estabilizada cerca de três horas depois, mas o monitoramento permanece ativo.
Quais serviços foram afetados
A lista é extensa e inclui serviços populares e críticos:
- ChatGPT
- X (antigo Twitter)
- Sendbot
- Plataformas de inteligência artificial
- Sites de notícias
- Sistemas de login
- APIs de diversos setores
- Portais públicos internacionais
O pico no Downdetector passou de 5 mil reclamações simultâneas.
Em vários países, inclusive no Brasil, usuários enfrentaram:
- páginas fora do ar;
- erros 500, 502 e 503;
- sites carregando lentamente;
- páginas que abriam e logo em seguida falhavam.

Por que essa falha teve impacto global
A infraestrutura da internet moderna é muito mais centralizada do que a maioria imagina.
Milhões de sites dependem da Cloudflare para continuarem online, especialmente para:
- proteger contra ataques;
- acelerar entregas de conteúdo;
- garantir estabilidade;
- distribuir tráfego;
- manter dados em cache na borda.
Quando uma peça tão grande dessa engrenagem falha, mesmo que parcialmente, o impacto se espalha automaticamente.
Essa dependência é chamada de “ponto de concentração de risco”: quando muitas aplicações usam o mesmo fornecedor para funções críticas.
Lições importantes para desenvolvedores e administradores
Mesmo sendo uma falha causada por um arquivo interno, há pontos importantes a considerar:
1. Ter redundância sempre que possível
Não depender 100% de uma única camada de proxy, CDN ou firewall.
2. Monitoramento constante
Taxas de erro acima do normal devem acionar alertas imediatamente.
3. Estratégia de fallback
Páginas estáticas e serviços essenciais podem continuar funcionando mesmo durante falhas externas.
4. Comunicação eficiente
Informar visitantes e clientes reduz perda de confiança.
5. Validação de regras dinâmicas
Sistemas que geram configurações automaticamente precisam de limites rígidos.
Curiosidade técnica
O mais curioso desse incidente é que ele foi provocado por algo pequeno no papel: um simples arquivo de configuração com mais regras do que o previsto.
Esse tipo de problema não é comum, mas lembra ao mundo que até infraestruturas gigantescas podem ser afetadas por detalhes internos.
Situação atual
A Cloudflare reportou que o problema está mitigado, mas pequenos reflexos ainda podem ocorrer enquanto a rede se estabiliza completamente.
Sites que dependem fortemente da camada de proxy continuam sendo monitorados de perto.
Conclusão
A falha de hoje mostrou o tanto que dependemos de empresas como a Cloudflare para manter a internet funcionando.
Mesmo que a causa tenha sido interna e sem relação com ataques, o impacto foi sentido globalmente.
Para quem trabalha com sites, servidores e plataformas digitais, esse evento reforça a importância de:
- arquitetura resiliente;
- sistemas de contingência;
- logs confiáveis;
- múltiplas camadas de proteção;
- comunicação transparente com usuários.



